Hypothesis testing 3
Recall, from Hypothesis testing 2, the problem
The fuel efficiency, in miles per gallon, of the Vauxwagen Etcetera is \mu _{0}=38.5 with a known standard deviation of \sigma _{0}=3.2. The company claims that it has improved the fuel efficiency of its latest model, and in support of that claim cites evidence from the testing of ten new cars under normal conditions; the new cars had an average fuel efficiency of m=40.3 miles per gallon.
How good is the evidence for the company's claim?
We originally solved this problem by noting that the test statistic
\frac{m-\mu _{0}}{\sigma _{0}/\sqrt{n}}
is distributed N(0,1). Its value is 1.778, and
P\left(Z>1.778\right)=0.0377,
meaning that if the null hypothesis were true, it is unlikely that the difference would be ths extreme (or more) through pure random variation.
In fact, that's not usually how we do things. Instead, we decide in advance what the cutoff point for unlikely ought to be (0.05 is pretty common, but not universal), and then find the value of the test statistic associated with that probability (which we call the critical value).
If the actual value is more extreme (that is, further from zero) than this critical value, then we regard the effect as significant and reject the null hypothesis.
Let's make 0.05 our cutoff point for this problem (this is called testing at the 5% level). We're then after the value z such that
P\left(Z>z\right)=0.05,
or (equivalently)
P\left(Z<z\right)=0.95.
This turns out to be 1.645. Since the actual value is more extreme than this, we reject the null hypothesis: the fuel efficiency really does seem to have improved.
Note, though, that testing at the 5% level is pretty arbitrary. If we need stronger evidence, we could (for example) test at the 2% level. In this case, the critical value is the value of z such that
P\left(Z<z\right)=0.98,
which is 2.054. The actual value of our test statistic is less extreme than this, meaning that we would accept the null hypothesis at the 2% level.
In general, the smaller the level, the sterner the test of the alternative hypothesis: that is, the stronger the evidence we require before rejecting the null hypothesis.
Two-tailed tests
Consider the following problem
A study is carried out into the effects of music on concentration. Twenty volunteers were sorted, as homogenously as possible, into two groups, and made to perform a corpus of 40 mental tasks. The first group worked with loud hip-hop in the background, whereas the second worked to equally loud metal. The scores out of 40 in the first group were 21, 19, 25, 23, 29, 22, 22, 24, 23 and 22. Those in the second group were 23, 20, 16, 21, 18, 21, 29, 20, 25 and 19. Test at the 5% level whether there is any significant difference. You may assume a common standard deviation.
Here, we're testing the difference between two means, with standard deviations estimated from the samples. The means are m_{1}=23.0 and m_{2}=21.2 respectively, and the sample standard deviations are 2.67 and 3.71 respectively. The common standard deviation is
s=\sqrt{\frac{\left(n_{1}-1\right)s_{1}^{2}+\left(n_{2}-1\right)s_{2}^{2}}{n_{1}+n_{2}-2}}=3.23,
and the test statistic is
\frac{m_{1}-m_{2}}{s\sqrt{1/n_{1}+1/n_{2}}},
which is distributed
t\left(n_{1}+n_{2}-2\right)=t\left(18\right).
The value of the test statistic is 1.247.
Now, here's the difference between this situation and the previous one. Before, we were interested in testing whether there had been an improvement: that is, a directional change. Here, we want to test whether there has been a change of any kind: that is, a change in either direction. This is called a two-tailed test.
To carry out a two-tailed test at the 5% level, we need to find the values of x such that, for a random variable T\sim t(18),
P\left(T>x\,\text{or}\,T<-x\right)=0.05.
Figure 1 illustrates the region concerned (known as the critical region).
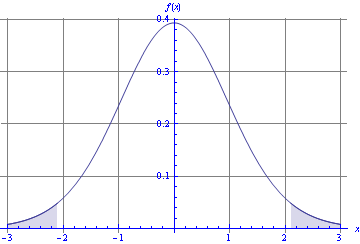
Figure 1: Critical region for a two-tailed t-test at the 5% level
This is clearly the same as finding that value of x for which
P\left(T>x\right)=0.025
or indeed
P\left(T<x\right)=0.975.
This critical value turns out to be 2.101, and our actual value is less extreme; there is no good evidence for a difference.
Tabulations
To carry out one-tailed tests at the 5% level, we need the 95th percentage point of all the t-distributions up to t(30), plus that of N(0,1).
\begin{array}{ccccc}t\left(2\right)&t\left(3\right)&t\left(4\right)&t\left(5\right)&t\left(6\right)\\2.91999&2.35336&2.13185&2.01505&1.94318\\\text{--}&\text{--}&\text{--}&\text{--}&\text{--}\\t\left(7\right)&t\left(8\right)&t\left(9\right)&t\left(10\right)&t\left(11\right)\\1.89458&1.85955&1.83311&1.81246&1.79588\\\text{--}&\text{--}&\text{--}&\text{--}&\text{--}\\t\left(12\right)&t\left(13\right)&t\left(14\right)&t\left(15\right)&t\left(16\right)\\1.78229&1.77093&1.76131&1.75305&1.74588\\\text{--}&\text{--}&\text{--}&\text{--}&\text{--}\\t\left(17\right)&t\left(18\right)&t\left(19\right)&t\left(20\right)&t\left(21\right)\\1.73961&1.73406&1.72913&1.72472&1.72074\\\text{--}&\text{--}&\text{--}&\text{--}&\text{--}\\t\left(22\right)&t\left(23\right)&t\left(24\right)&t\left(25\right)&t\left(26\right)\\1.71714&1.71387&1.71088&1.70814&1.70562\\\text{--}&\text{--}&\text{--}&\text{--}&\text{--}\\t\left(27\right)&t\left(28\right)&t\left(29\right)&t\left(30\right)&N\left(0,1\right)\\1.70329&1.70113&1.69913&1.69726&1.64485\end{array}
To carry out two-tailed tests at the 5% level, we need the 97.5th percentage point of all the t-distributions up to t(30), plus that of N(0,1).
\begin{array}{ccccc}t\left(2\right)&t\left(3\right)&t\left(4\right)&t\left(5\right)&t\left(6\right)\\4.30265&3.18245&2.77645&2.57058&2.44691\\\text{--}&\text{--}&\text{--}&\text{--}&\text{--}\\t\left(7\right)&t\left(8\right)&t\left(9\right)&t\left(10\right)&t\left(11\right)\\2.36462&2.306&2.26216&2.22814&2.20099\\\text{--}&\text{--}&\text{--}&\text{--}&\text{--}\\t\left(12\right)&t\left(13\right)&t\left(14\right)&t\left(15\right)&t\left(16\right)\\2.17881&2.16037&2.14479&2.13145&2.11991\\\text{--}&\text{--}&\text{--}&\text{--}&\text{--}\\t\left(17\right)&t\left(18\right)&t\left(19\right)&t\left(20\right)&t\left(21\right)\\2.10982&2.10092&2.09302&2.08596&2.07961\\\text{--}&\text{--}&\text{--}&\text{--}&\text{--}\\t\left(22\right)&t\left(23\right)&t\left(24\right)&t\left(25\right)&t\left(26\right)\\2.07387&2.06866&2.0639&2.05954&2.05553\\\text{--}&\text{--}&\text{--}&\text{--}&\text{--}\\t\left(27\right)&t\left(28\right)&t\left(29\right)&t\left(30\right)&N\left(0,1\right)\\2.05183&2.04841&2.04523&2.04227&1.95996\end{array}
To carry out one-tailed tests at the 2% level, we need the 98th percentage point of all the t-distributions up to t(30), plus that of N(0,1).
\begin{array}{ccccc}t\left(2\right)&t\left(3\right)&t\left(4\right)&t\left(5\right)&t\left(6\right)\\4.84873&3.48191&2.99853&2.75651&2.61224\\\text{--}&\text{--}&\text{--}&\text{--}&\text{--}\\t\left(7\right)&t\left(8\right)&t\left(9\right)&t\left(10\right)&t\left(11\right)\\2.51675&2.44898&2.39844&2.35931&2.32814\\\text{--}&\text{--}&\text{--}&\text{--}&\text{--}\\t\left(12\right)&t\left(13\right)&t\left(14\right)&t\left(15\right)&t\left(16\right)\\2.30272&2.2816&2.26378&2.24854&2.23536\\\text{--}&\text{--}&\text{--}&\text{--}&\text{--}\\t\left(17\right)&t\left(18\right)&t\left(19\right)&t\left(20\right)&t\left(21\right)\\2.22385&2.2137&2.2047&2.19666&2.18943\\\text{--}&\text{--}&\text{--}&\text{--}&\text{--}\\t\left(22\right)&t\left(23\right)&t\left(24\right)&t\left(25\right)&t\left(26\right)\\2.18289&2.17696&2.17154&2.16659&2.16203\\\text{--}&\text{--}&\text{--}&\text{--}&\text{--}\\t\left(27\right)&t\left(28\right)&t\left(29\right)&t\left(30\right)&N\left(0,1\right)\\2.15782&2.15393&2.15033&2.14697&2.05375\end{array}
To carry out two-tailed tests at the 2% level, or one-tailed tests at the 1% level, we need the 99th percentage point of all the t-distributions up to t(30), plus that of N(0,1).
\begin{array}{ccccc}t\left(2\right)&t\left(3\right)&t\left(4\right)&t\left(5\right)&t\left(6\right)\\6.96456&4.5407&3.74695&3.36493&3.14267\\\text{--}&\text{--}&\text{--}&\text{--}&\text{--}\\t\left(7\right)&t\left(8\right)&t\left(9\right)&t\left(10\right)&t\left(11\right)\\2.99795&2.89646&2.82144&2.76377&2.71808\\\text{--}&\text{--}&\text{--}&\text{--}&\text{--}\\t\left(12\right)&t\left(13\right)&t\left(14\right)&t\left(15\right)&t\left(16\right)\\2.68100&2.65031&2.62449&2.60248&2.58349\\\text{--}&\text{--}&\text{--}&\text{--}&\text{--}\\t\left(17\right)&t\left(18\right)&t\left(19\right)&t\left(20\right)&t\left(21\right)\\2.56693&2.55238&2.53948&2.52798&2.51765\\\text{--}&\text{--}&\text{--}&\text{--}&\text{--}\\t\left(22\right)&t\left(23\right)&t\left(24\right)&t\left(25\right)&t\left(26\right)\\2.50832&2.49987&2.49216&2.48511&2.47863\\\text{--}&\text{--}&\text{--}&\text{--}&\text{--}\\t\left(27\right)&t\left(28\right)&t\left(29\right)&t\left(30\right)&N\left(0,1\right)\\2.47266&2.46714&2.46202&2.45726&2.32635\end{array}
To carry out two-tailed tests at the 1% level, we need the 99.5th percentage point of all the t-distributions up to t(30), plus that of N(0,1).
\begin{array}{ccccc}t\left(2\right)&t\left(3\right)&t\left(4\right)&t\left(5\right)&t\left(6\right)\\9.92484&5.84091&4.60409&4.03214&3.70743\\\text{--}&\text{--}&\text{--}&\text{--}&\text{--}\\t\left(7\right)&t\left(8\right)&t\left(9\right)&t\left(10\right)&t\left(11\right)\\3.49948&3.35539&3.24984&3.16927&3.10581\\\text{--}&\text{--}&\text{--}&\text{--}&\text{--}\\t\left(12\right)&t\left(13\right)&t\left(14\right)&t\left(15\right)&t\left(16\right)\\3.05454&3.01228&2.97684&2.94671&2.92078\\\text{--}&\text{--}&\text{--}&\text{--}&\text{--}\\t\left(17\right)&t\left(18\right)&t\left(19\right)&t\left(20\right)&t\left(21\right)\\2.89823&2.87844&2.86093&2.84534&2.83136\\\text{--}&\text{--}&\text{--}&\text{--}&\text{--}\\t\left(22\right)&t\left(23\right)&t\left(24\right)&t\left(25\right)&t\left(26\right)\\2.81876&2.80734&2.79694&2.78744&2.77871\\\text{--}&\text{--}&\text{--}&\text{--}&\text{--}\\t\left(27\right)&t\left(28\right)&t\left(29\right)&t\left(30\right)&N\left(0,1\right)\\2.77068&2.76326&2.75639&2.75000&2.57583\end{array}